之前老师讲过两个不等式:
-
马尔科夫不等式
P(X≥t)≤tE(X)
-
切比雪夫不等式
令 Y=[X−E(X)]2
P(Y≥t2)≤t2E(Y)=t2D(X)
随机变量偏离它的期望一个给定的值的概率,被称为偏差的尾概率(tail probability)。尾概率的计算方式除了利用已知条件直接计算以外,还有很多『模板』可以使用,就包括:
- 马尔科夫(Markov)不等式
- 切比雪夫(Chebyshev)不等式
- 切尔诺夫(Chernoff)界
简单来说尾概率就是 P(X>t) 的范围主要由计数计算概率法和利用数字特征计算的方法。
这篇文章将详细介绍切尔诺夫界,以及鞅的相关概念和应用。
- 切尔诺夫界:『独立随机变量的和』的分布的尾概率的一般的界,通过矩生成函数得到,有『切尔诺夫型』、『指数形式』尾概率界等。
- 鞅:对不能抽象为『独立随机变量的和』的应用场景,鞅可以得到随机变量偏离期望的程度的界。
切尔诺夫界
矩生成函数
定义:随机变量 X 的矩生成函数是关于实数 t 的函数:
MX(t)=E[etX]
由麦克劳林级数可知
E[etX]=E[k=0∑∞k!(tX)k]=k=0∑∞k!tkE(Xk)(1)
将 (1) 式对 t 求 n 阶导,并令 t=0,可以得到 X 的各阶矩。
MX(n)(t)MX(n)(0)=E(Xn)+11tE(Xn+1)+21t2E(Xn+2)+⋯=E(Xn)
(另外一种更简单的证明在《概率与计算》上,直接利用期望和微分运算可以交换的性质。)
矩生成函数有下面几个性质:
-
矩生成函数相同,则随机变量分布相同。令 X 和 Y 是两个随机变量,如果对某个 δ>0,对于所有的 t∈(−δ,δ) 有 MX(t)=MY(t),那么 X 和 Y 有相同的分布。
-
随机变量的各阶矩相同,则这两个随机变量分布相同。
-
独立随机变量的和的矩生成函数等于各自生成函数的积。
E[et(X+Y)]=E[etX⋅etX]=E[etX]⋅E[etY]
两点分布和二项分布的矩生函数
投掷一枚硬币,结果用 X 表示,正面朝上的概率为 p;投掷 n 次的总结果用 Y 表示。
MX(t)=E(etX)=p⋅et⋅1+(1−p)⋅et⋅0=1−p+pet(2)
我们可以利用 (2) 计算 X 的一阶矩(均值)和二阶矩,从而得到方差。
E(X)=MX(1)(0)=(pet)∣t=0=p
E(X2)=MX(2)(0)=(pet)∣t=0=p
D(X)=E(X2)−E2(X)=p−p2=p(1−p)
再来计算 Y 的矩生成函数,Y 是由 n 个独立同分布的 X 得来的。两个独立随机变量之和的生成函数等于这两个随机变量的矩生成函数之积:
MY(t)=E(etY)=E(et∑inXi)=E(etXin)=E(etXi)n=[MX(t)]n=(1−p+pet)n(3)
MY(1)(t)=n(1−p+pet)n−1⋅pet=npet(1−p+pet)n−1
求导:
MY(2)(t)=npet(1−p+pet)n−1+npet⋅(n−1)(1−p+pet)n−2⋅pet=npet(1−p+pet)n−1+n(n−1)p2e2t⋅(1−p+pet)n−2
取在 t=0 处的值:
E(Y)=[npet(1−p+pet)n−1]∣t=0=np(1−p+p)=np
E(Y2)=[npet(1−p+pet)n−1+n(n−1)p2e2t⋅(1−p+pet)n−2]t=0=np+n(n−1)p2
计算方差:
D(Y)=E(Y2)−E2(Y)=[np+n(n−1)p2]−(np)2=np+n2p2−np2−n2p2=np(1−p)
切尔诺夫界的导出
定理:X1,⋯,Xn 是独立泊松实验,P(Xi=1)=pi,X=∑i=1nXi,μ=E(X),则对任意 δ>0,有:
P[X≥(1+δ)μ]<[(1+δ)1+δeδ]μ
泊松实验并不是符合泊松分布的随机变量,而是 0-1 随机变量。在泊松试验中,随机变量的分布不必相等,伯努利试验是泊松试验的一种特殊情形,其中独立的 0-1 随机变量有相同的分布。可以看到定理中为每个实验用了不同 pi 表示其分布。
在 μ=50 时,右式图像大概如此(使用 https://www.desmos.com/calculator 绘制,只看 δ>0 部分):
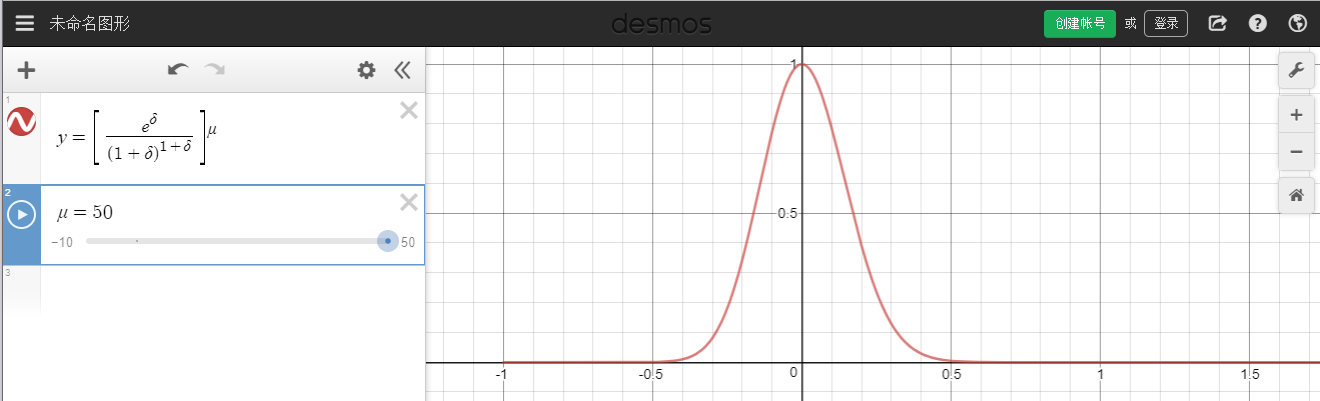
直观理解为:X 的值超过其均值百分比 δ 的概率不会超过后面那一长串,而且后面那个式子在 δ=0 时为 1,在 δ=∞ 时为 0,直观上很容易理解,也很好记。
切尔诺夫界提供了估计尾概率 P(X>t) 的新工具,虽然我们之前已经有了类似的工具(Markov、Chebyshev),但是这个结果更加精确。
先给出定理,再给出证明经常是一个很好的教学模式,我们接下来证明这个定理。
-
计算 X 的矩生成函数
MX(t)独立性i=1∏nMXi(t)(4)
其中
MXi(t)=P(Xi=1)et⋅1+P(Xi=0)et⋅0=piet+(1−pi)e0=1−pi+piet≤epi(et−1),这里用到了1+x≤ex在R上恒成立的条件
将放缩应用于 (4) 式,得到一个比较好的形式:
MX(t)独立性i=1∏nMXi(t)≤i=1∏nepi(et−1)=exp{(et−1)i=1∑npi}=exp{(et−1)μ},这里用到了μ=E(X)=p1+⋯+pn
-
要计算 P(X≥t),等价于计算 P(h(X)≥h(t))(在 h 是增函数时)。应用 Markov 不等式 P[h(X)≥h(t)]≤h(t)E[h(X)]
P(X>t)=P(eλX>eλt),注意λ>0满足增函数≤eλtE(eλX),对随机变量eλX应用Markov不等式≤expλtexp{(eλ−1)μ}
这里要尽量求出小的上界,因此取一个极小值:
P(X>t)≤λ>0minexpλtexp{(eλ−1)μ}
-
针对 t 进行优化,得出结论
令 t=(1+δ)μ(为什么,因为概率内部取的是大于号 X>t,所以求偏离均值以上更有用,这样后面的 λ 取特殊值才能保证是大于 0 的),有
P[X>(1+δ)μ]≤λ>0minexp{λ(1+δ)μ}exp{(eλ−1)μ}令λ=ln(δ+1),既然小于所有中最小的,肯定也小于特例,δ>0≤(1+δ)(1+δ)μeδμ=[(1+δ)(1+δ)eδ]μ(5)
切尔诺夫界得证,在第 2 步中如果令 λ<0,并在第 3 步令 λ=ln(1−δ)(δ∈(0,1)) 还会得到另外一个形式:
P[X≤(1−δ)μ]≤[(1−δ)(1−δ)eδ]μ(6)
式 (5) 和式 (6) 总结起来就是:
⎩⎨⎧P[X>(1+δ)μ]≤[(1+δ)(1+δ)eδ]μ,δ>0P[X≤(1−δ)μ]≤[(1−δ)(1−δ)eδ]μ,δ∈(0,1)(7)
切尔诺夫界的常用形式
式 (7) 虽然精确,但是计算较复杂,我们可以得出一个可以忍受的、不太精确但是计算量较小的尾不等式:
⎩⎨⎧P[X>(1+δ)μ]≤[(1+δ)(1+δ)eδ]μ≤exp3−μδ2,δ∈(0,1)(注意这里条件更强,限制δ必须小于1,下同)P[X≤(1−δ)μ]≤[(1−δ)(1−δ)eδ]μ≤exp2−μδ2,δ∈(0,1)(8)
又是先给结论再证明,真的不知道前辈们是怎么想出这个结论的,一定是数学思维超级好!
要证明 [(1+δ)(1+δ)eδ]μ≤exp3−μδ2,δ>0,取对数,等价于证明:
μln[(1+δ)(1+δ)eδ]≤3−μδ2
令 f(δ)=(左边−右边)/μ,要证明 f(δ)≤0,由于 f(0)=0,只需要证明 f′(δ)<0。求导即可。
f(δ)=δ−(1+δ)ln(1+δ)+3δ2=3δ2+δ−(1+δ)ln(1+δ)
f′(δ)=32δ+1−ln(1+δ)−(1+δ)1+δ1=32δ−ln(1+δ)
要证明 f′(δ)>0,需要进一步求导,得到:
f′′(δ)=32−1+δ1
f′′(δ) 是增函数,由于规定 δ∈(0,1),所以 f′′∈(−31,61),因此 f′ 先减后增,要证明 f′<0,只需求证两个端点 f(0) 和 f(1) 即可。
同样的可以证明第二种情况。
最终我们还可以将两者综合运用,得到一个更好的式子,『偏离均值』=『偏离均值之下』或者『偏离均值之下』。
P[∣X−μ∣≥δμ]≤P[X≤(1−δ)μ]+P[∣X≥(1+δ)μ]=exp2−μδ2+exp3−μδ2=a+b≤2b=2exp3−μδ2(9)
可以看到限制 δ<1 之后,我们得到了分母带 3 的那个结论,我们可以进一步限制 t>2eμ,得到更简洁的结论。
P(X>t)<2−t(10)
证明:设 t=(1+δ)μ,对于 t≥2eμ,δ+1=μt≥2e。因此,
P[X≥(1+δ)μ]≤((1+δ)1+δeδ)μ≤((1+δ)1+δeδ+1)μ=(1+δe)(1+δ)μ≤2−(1+δ)μ=2−t
切尔诺夫界的简单应用
成功实验的总次数
独立同分布重复均匀硬币硬币 Bernoulli 实验 n 次,Xi=1 表示第 i 次实验成功,X 表示成功实验的总次数。X=∑i=1nXi,E(X)=nE(Xi)=2n。
这里有更强的条件,如上文所述,伯努利试验是泊松实验的特殊形式。
使用 (9) 式,我们可以得到:
P[∣X−μ∣≥δμ]P[∣X−2n∣≥21μ]≤2exp{3−μδ2}≤2exp{−12μ}=2exp{−24n}
我们得到的这个不等式的意思是:成功实验的总次数 X 均值为 2n,X 的实际取值偏离均值 50% 的概率不超过 2exp{−24n}。
算法重复遍数
曾经我们讲过拉斯维加斯算法,它的特点是:
- 得到的解一定是正确的,
- 运行时间不确定,运行时间与运行一次能够得到解得的概率 p 有关。
之前举的是 LASYSELECT 的例子,算法的目的是从 S 中选出第 k 小的元素,算法运行一遍得到解的概率为 p重复调用算法知道得到问题的解所需要的运行次数我们设为随机变量 X,X 服从几何分布。
E(X)=p1
我们现在求一个对算法运行次数的估计范围,运行次数在这个范围内的概率足够大,以至于我们可以认为算法运行次数基本就是此范围。
老师课件中此处有错误,下面是我的证明。
由切尔诺夫界:
E(∣X−μ∣≥δμ)<2exp{−μδ2/3}=p0,μ=p1
解得:
δ0=−3p(lnp0−ln2)
结论:算法运行遍数以 1−p0 的概率介于 (1−δ0)μ 和 (1+δ0)μ 之间。
参数估计
某基因突变的概率为 p(未知),我们要用统计规律来估计 p,进行 n 次实验,测得突变 X 次,q=X/n,我们要判断:q≈p 可不可信?
我们要的结论是 P(p∈/[q−δ,q+δ])<1−γ,也就是说 p 在区间 [q−δ,q+δ] 之外的概率足够小,比如 0.01(γ=0.99)。其中 [q−δ,q+δ] 称为置信区间,γ 称为置信水平。
我们要做的是将实验次数 n 和置信水平 γ 关联起来。
分成两半:
P(p∈/[q−δ,q+δ])=P(p<q−δ)+P(p>q+δ)
p<q−δ⇔p<X/n−δ⇔X>(p+δ)n⇔X>(1+δ/p)pn
p>q+δ⇔p>X/n+δ⇔X<(1−δ/p)pn
均值 μ=E(X)=pn,因此有:
P(p∈/[q−δ,q+δ])=P[∣X−μ∣>(δ/p)μ]≤2exp{−3μ(δ/p)2}=2exp{−3pnδ2}≤2exp{−3nδ2}
- 令其为 1−γ,解得 δ0,得到置信区间
- 知道置信区间,直接计算出置信水平
- 直到置信区间和置信水平,可以得到实验所需次数
注:老师课上推到的时候没有把大于和小于两种情况合并,所以结果是 exp{−2nδ2}+exp{−3nδ2},差别不会很大。
【作业】 π 值估计精度与抽样次数 n 之间的关系

算法重述:
有一个半径为 r 的圆及其外切四边形,向正方形随机投掷 n 个点,设有 X 个点落入圆内(X 就是我们要考虑的随机变量),投掷点落入圆内的概率为 (πr2)/(4r2)=4π。我们用 X/n 逼近 π/4,即 X/n=π/4,于是 π≈(4X)/n。
这与【参数估计】的例子是完全一样的,这里相当于重证一遍。
每一次投掷,落入圆形区域记为成功,概率为 p,显然 p=π/4。连续 n 次实验,得到的对 p 的估计值记为 q=X/n。
需要对不等式 P(p∈/[q−δ,q+δ])<1−γ 进行求解。
分成两半:
P(p∈/[q−δ,q+δ])=P(p<q−δ)+P(p>q+δ)
上个问题中我们是合并求解的,现在把左半部分和右半部分分开求解,得到更精确的结论。
左半部分:
p<q−δ⇔p<X/n−δ⇔X>(p+δ)n⇔X>(1+δ/p)pn
因为 μ=pn,所以:
P(X>(1+δ/p)pn)=P(X>(1+δ/p)μ)≤exp{−3μ(δ/p)2}=exp{−3pn(δ/p)2}=exp{−3pnδ2}
注意,这里是与老师唯一的区别,我们知道 p=4π,所以不必再放缩消去 p,从而也会得到更加精确的结论。
右半部分:
p>q+δ⇔p>X/n+δ⇔X<(1−δ/p)pn
同样地,有:
P(X<(1−δ/p)pn)=P(X<(1−δ/p)μ)≤exp{−2μ(δ/p)2}=exp{−2pn(δ/p)2}=exp{−2pnδ2}
最终把它们加起来,有:
P(p∈/[q−δ,q+δ])=P(p<q−δ)+P(p>q+δ)≤exp{−3pnδ2}+exp{−2pnδ2}=exp{−3π4nδ2}+exp{−2π4nδ2}
现在要的是『抽样次数 n』与『求解精度 δ』之间的关系。
我们固定置信度为 γ=0.95,得到 n 与 δ 之间的隐函数关系:
exp{−3π4nδ2}+exp{−2π4nδ2}=1−0.95=0.05
绘制图像如下:
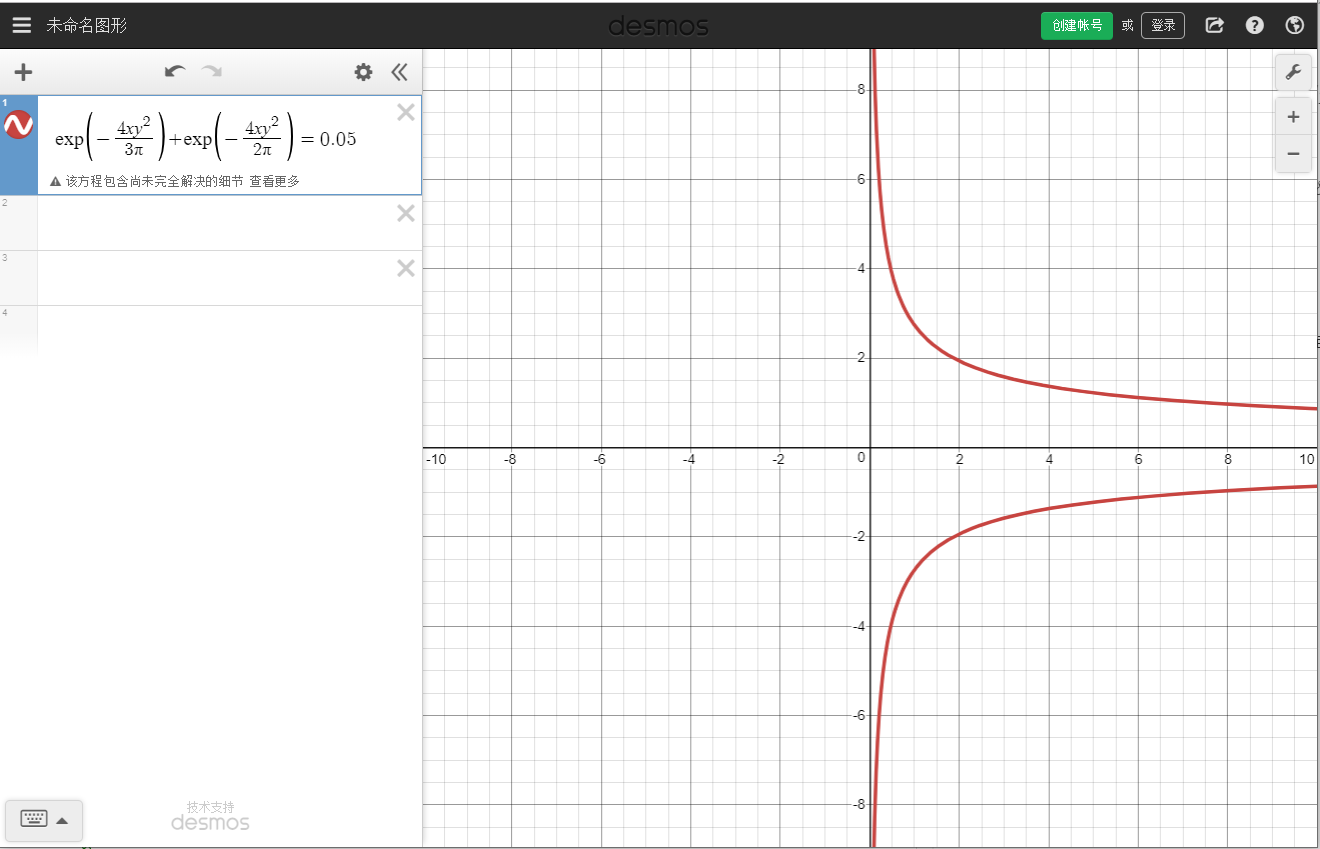
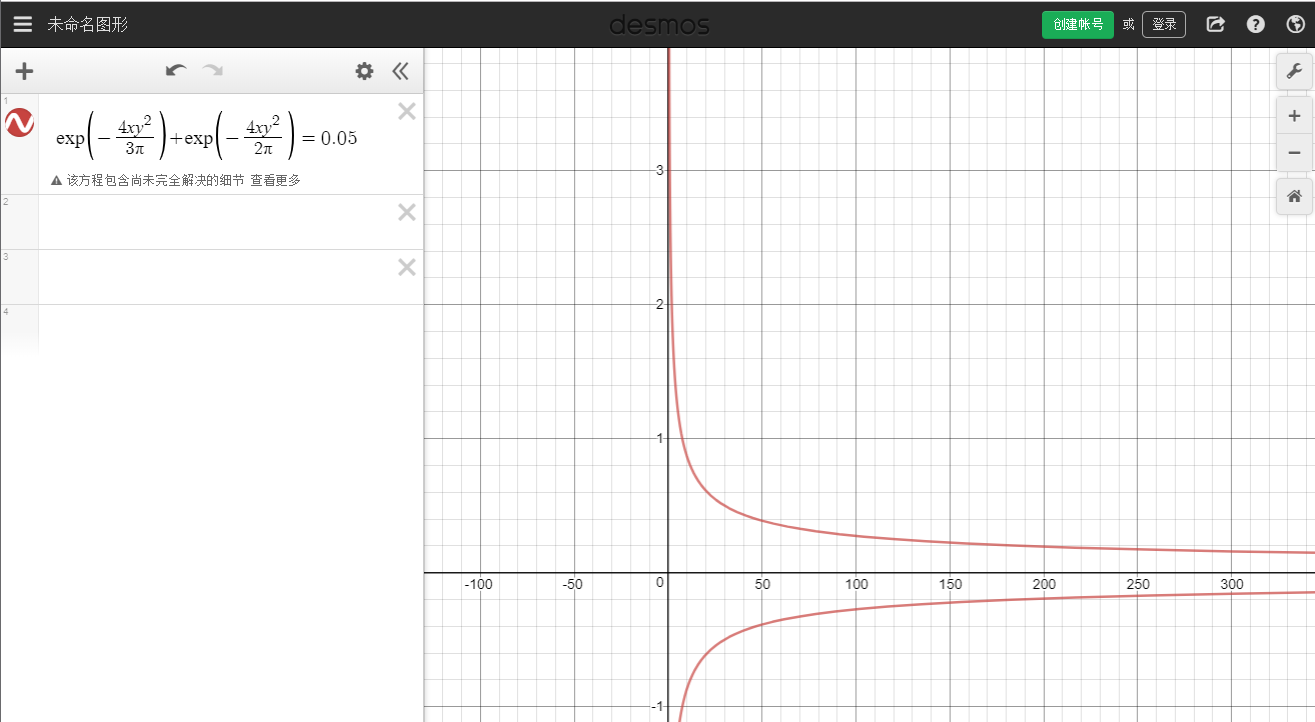
可以看到,随着 n 的增加,置信区间缩小,精度越来越好,从网格中可以看出 n=300 时精度达到了 0.1。
【作业】快排的随机性

这道题来自《概率与计算》习题 4.20,答案参见这里。
(a)
用 D(s) 表示 QuickSort 排序时所发生的动作对应的树的高度。我们用 N(s) 表示排序 s 个数对应的结点。对于树中有两个孩子 N(a) 和 N(s−a) 的结点 N(s),我们有下面的递归等式:
D(s)=max{D(a),D(s−a)}+1
其中 D(1)=1,D(s) 是关于 s 的单调不减的函数。每次迭代 D(s) 表示一个结点,此结点有两个孩子 D(a) 和 D(s−a)。由题,一个结点 N(s),带有两个孩子结点 N(a) 和 N(s−a),如果满足 max{a,s−a}≤2s/3,也就是说 max{D(a),D(s−a)}≤D(2s/3)。因此对于一个好结点,我们有 D(s)≤D(2s/3)+1。这样,在任何路径上,从根结点到叶子结点的好结点的数量最多为 log3/2n=log2(2/3)⋅log2n,取 log2(2/3)≈0.631 为所要求的 c1 即可。
(b)
不超过,至少 <-> 超过,至多 <-> 切尔诺夫
令 c2=36(也就是说,从树根到叶子的路径上所含结点的数量至少为 35)、δ=9/20。通过 (a) 我们知道任意从根到叶子结点的路径上好结点的数量不超过 c1log2n,其中 c1≈0.631,可以推出坏结点的数量至少是 35log2n。令 Xi 表示一个指示随机变量,Xi=1 表示第路径上第 i 个结点是坏的,否则 Xi=0。我们要估计的概率就是 P[X=∑i=136log2nXi≥35.369log2n]。注意一个结点是好的当且仅当选中的基准元素大于等于第 s/3 小的元素,或者小于等于第 2s/3 小的元素。因此我们有 P(Xi=1)≤2/3,P(Xi=0)≥1/3,E(Xi)≤(2/3)⋅36log2n=24log2n。另外,根据切尔诺夫界,我们有:
令 μH=24log2n,我们有:
P[X≥35.369log2n]≤P[X≥34.8log2n]=P[X≥(1+δ)⋅μH]≤exp{−μHδ2/3}=exp{−5081⋅ln2lnn}≤n−2.337<n−2
因此我们得到了所要求的概率 1−1/n2。
©
注意到树中从根到叶子结点的路径一共有 n 条。用 Ai 表示事件:在第 i 条路径上结点的总数超过 c2log2n(c2 在 (b) 中确定为 36)。我们已经证明 P(Ai)≤1/n2。因此根据 union-bound,从根到叶子结点的最长的路中的结点数大于 c2log2n 的概率为 P(∪i=1nAi),至多是 ∑i=1nP(Ai)=n1。得证。
(d)
用 T(n) 表示 Quicksort 排序 n 个数时用的时间,我们有:
T(n)=T(a)+T(n−a)+O(n)
其中 O(n) 是基准元素和其他 n−1 个元素进行比较时的时间开销。因为 Quicksort 算法的递归深度至多等于相应的树的从根到叶子结点的路上的结点数量,因为以 1−n1 的概率为 O(logn),通过使用递归树方法,分析可得以 1−n1 的概率 T(n)=O(nlogn)。
鞅
鞅的应用
随机变量序列 X0,X1,X2,⋯,如果满足
E(Xi∣X0,X1,⋯,Xi−1)=Xi−1,∀i≥1
则称 X0,X1,X2,⋯ 是一个鞅。
【习题】按照定义证明

根据定义,只需证明
E(Yi∣Y0,Y1,⋯,Yi−1)=Yi−1,∀i≥1
E(Yi∣Y0,Y1,⋯,Yi−1)=E(2i(1−Xi)∣Y0,Y1,⋯,Yi−1)=2i−2iE[Xi∣Y0,Y1,⋯,Yi−1]
根据已知条件:
E(Xi∣Xi−1)=(Xi−1+1)/2
因为 Yi 给定就相当于 Xi 给定,所以:
E(Yi∣Y0,Y1,⋯,Yi−1)=2i−2iE[Xi∣X0,X1,⋯,Xi−1]=2i−2iE[Xi∣Xi−1]=2i−2i2Xi−1+1带回去2i(1−21−2i−1Yi−1+1)=Yi−1
【习题】应用-分析时间复杂度

步骤 4 处每次执行 goto 的条件为,从剩余的 n-(k-1) 个数中选取出的数小于之前抽取的数。
这是一个 Las Vegas 算法,假设每一次执行:
- 成功的概率为 p,所用的时间为 O(n)。
- 不成功的概率为 1−p,所用的时间为 O(Ji),i 表示第几次执行,其中 Ji 为第一个满足 yk<yk−1 的 k,J 的期望为 E(Ji)。
由几何分布的性质,所需的运行次数 X 的期望值为:
E(X)=p1
算法运行所需的总时间等于不成功时所需要的时间加上最后一次成功时所需要的时间:
T=i=1∑X−1O(Ji)+O(n)
因此算法运行的时间复杂度的期望为:
看这里,补习概率论知识,随机变量作 sum 的下标时该怎么办。
E(i=0∑NXi)=n∑P(N=n)E(i=0∑nXi)
E(T)=E[i=1∑X−1O(Ji)+O(n)]=E[i=1∑X−1O(Ji)]+O(n)=x∑P(X=x)E(i=1∑x−1O(Ji))+O(n)每一轮运行J的均值都是一样的,记为E(J)=x∑P(X=x)(x−1)O[E(J)]+O(n)=O[E(J)]x∑P(X=x)(x−1)+O(n)=O[E(J)][E(X)−1]+O(n)=O[E(J)](p1−1)+O(n)
下面计算概率值:
- 所有可能的排序中只有 1 种是正确的(不考虑元素相等的情况),成功的概率 p=n!1。
- 『第 i 元素才开始打破有序性,前 (i−1) 个元素均有序』的概率为 P(J=i),前 (i−2) 个元素只有 1 种排法,第 (i−1) 个元素有两种排法,其中一种排法不管第 i 个元素选择什么都会打破有序性,另外一种排法要打破有序性必须第 i 个元素只有 (n−i) 种排法,第 (i+1) 个及后面的元素排法任意,P(J=i)=n![(n−i+1)!+(n−i)(n−i)!]<(n)!2(n−i+1)!。因此 E(J)=∑j=2nP(J=j)j<∑j=2nn!2(n−j+1)!j≤∑j=2nn!2(n−2+1)!j≤∑j=2nj=2(n−1)(n+2)
最后得到平均时间复杂度为:
E(T)=O(j=2∑nCnjj(n!−1)+n)≤O[O(n)(n!−1)+n]=O[(n+1)!]
虽然刚开始做出来了,后来却发现老师要求使用鞅的知识,所以看了一下课本,在《概率与计算》中有一道习题 12.12 和这个是一样的,不过并没有找到答案。
同样用 Ji 表示每次运行算法不成功时用去的时间,X 表示成功时的总尝试次数。在这个式子的基础上:
T=i=1∑X−1O(Ji)+O(n)
往瓦尔德方程的路子上靠,我们可以尝试去证明 X 是 J={J1,J2⋯} 的一个停时。
不同的 Ji 之间是相互独立的,有 E(Ji)=E(Ji−1),所以 J1,⋯ 是一个鞅。而且 X=x(X−1=x−1) 仅依赖于 J1,⋯,Jx,所以 X−1 是鞅 J 的一个停时。
所以有:
E[i=1∑X−1O(Ji)]=E(X−1)⋅E(J)
其余证明过程不变。
