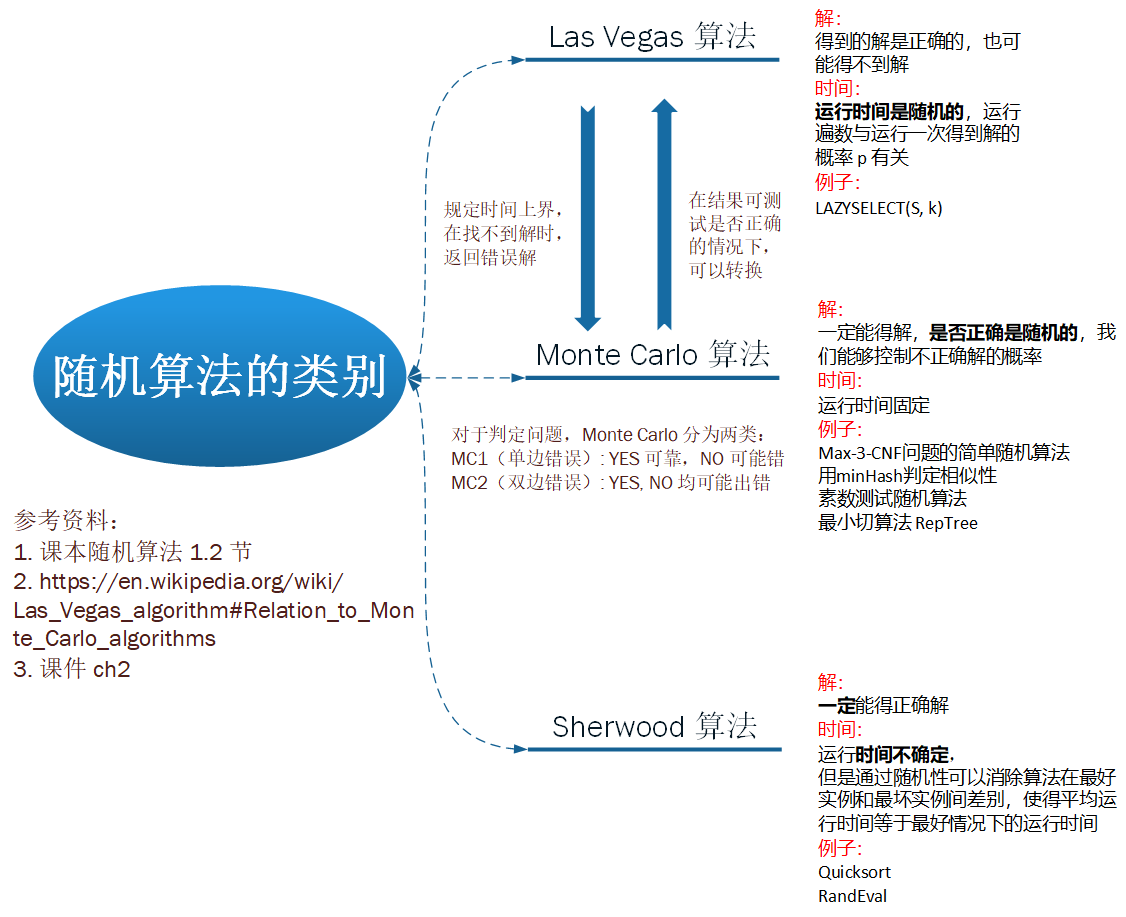
随机算法里面的 Las Vegas 算法、Monte Carlo 算法、姚期智不等式等等的习题。
习题一
1.1

(1)
该算法属于 Sherwood 算法,因为该算法一定会得到正确解,但运行时间不确定。
(2)
第一次考虑的集合大小为 n,将其分为 3 堆,长度分别为:∣S1∣,1,∣S2∣,令 l=∣S1∣,通过讨论 l 值来确定各种情况的概率:
- l<k−1: 此时就算加上元素 s 仍有 l+1<k,也就是说第 k 小元素一定出现在 S2 中,这对应于第 5 行。此时继续考虑 S2,而 S2 的长度在 (n-k+1) ~ (n-1) 之间,平均长度为 (n−2k)。
- l=k−1: 此时第 k 小元素一定是 s,这对应于第 3 行。此时算法结束。
- l>k−1: 此时第 k 小元素一定在 S1 中,这对应于第 4 行。此时继续考虑 S1,而 S1 的长度在 k ~ (n-1) 之间,平均长度为 2k+n−1。
注意,题目中第 4 行、第 5 行处的 k 应该改为 k−1 才对。
算法不能处理有相等值的情况,考虑极端情况所有数全相等的话,求出来的 S1,S2 都是空集
这三种情况出现的概率分别为:nk−2, n1, nn−k+1。
记算法第 i 层调用考虑的集合大小为 Zi。
这一层考虑的集合大小为 E(Z1)=n,第二轮考虑的集合大小的数学期望为:
E(Z2)=nk−2(n−2k)+nn−k+12k+n−1=2n2kn−k2−4n+2k+n2−k2+2k−1=2nn2+(2k−4)n−2k2+4k−1<2nn2+(2n−4)n−0+4n−1=2n3n2−1<23n
这样直接放缩不太精确,我们可以令 k=tn,t∈[n1,1],可以得到等式:
E(Z2)=(21+t−t2)n+(2t−2)−2n1<(21+t−t2)n
令 b=21+t−t2 即可, 此时 b∈[21,43],则有 E(Z2)<bn。
以此递推,不难得到:
E(Zi)<bin,i≥2
(3)
T(n)=E(Z1)+E(Z2)+⋯+E(Zm)+⋯<n+bn+b2n+⋯b∞n=1−bn=O(n)
(4)
改进算法,我们可以处理有相等数的情况。

代码实现如下:
1.2

算法的基本思想:只用实际值对等式进行验证是否成立,当验证的值足够多时,算法的正确性提高。
算法如下:
设 d=max(m+n,l),从 {1,⋯,100d} 中均匀随机地选取一个整数 t。计算 s(x)=p(x)q(x)−r(x) 的值。如果 s(t)=0,则算法判定等式成立;否则,算法判定等式不成立。
判断结果分析:
- 若等式成立,对于任意的 t,都有 s(t)=0,算法将给出正确的结论
- 若等式不成立,算法发现 s(t)=0,则给出正确的结论
- 若不等式成立,但是算法发现 s(t)=0,也就是说 t 恰好为 s(x)=0 旳根,由于 s(x) 的次数不大于 d,那么 s(x)=0 旳根的数量 m≤d,所以这种情况出现的概率 P(error)=100dm≤100dd=1001
综上所述,算法获得正确解得概率为 P(correct)≥10099。
时间复杂度分析:由于 s(x) 的次数不大于 d,算法的运行时间为 O(d)。
随机算法的类别:由于运行时间固定,但是可能给出不正确的解,所以此算法为 Monte Carlo 算法。
1.3

验证 Ap×qBq×r=Cp×r 是否成立。
算法的基本思想:类似于上一题,两边同乘以一个向量,结果相等时,认为等式成立。
算法如下:
随机抽取一个向量 s=(s1,s2,⋯,sr)T∈{0,1}n,然后计算 ABs,即先计算 Bs,再计算 A(Bs),同时计算 Cs。如果 A(Bs)=Cs,则 AB=C,否则返回 AB=C,但结果不一定正确。
算法的错误率 P(error) 为 AB=C 但 A(Bs)=Cs 的概率。
error 事件等价于事件 Dp×r=AB−C=0 但是 Ds=0,由于 D=0,所以其必有某个非零元素,不失一般性,设非零元素为 d11。考虑 D 第一行乘以 s 第 1 列(注意 s 只有一列):
j=1∑nd1jsj=0
等价地有:
s1=−d11∑j=2nd1jsj(1)
根据向量 s 的取法,我们可以认为每一个 si 都是独立均匀地从 {0,1} 中选取的。
现在考虑等式 (1),在右边值都确定的时候,s1 有两种选择(0, 1),但是使等式成立的值只有一个,所以等式成立的概率至多为 21,也就是说原等式 AB=C 的概率至多为 21,P(error)≤21。
算法的时间复杂度:
算法需要做 3 次矩阵-向量乘法:
- Bs:O(q×r)
- A(Bs):O(p×q)
- Cs:O(p×r)
总的时间复杂度为:O(max1(p,q,r)+max2(p,q,r)),其中 maxi(p,q,r) 表示 p, q 中第 i 大的元素。
算法的类型:由于运行时间确定,但是可能给出不正确的结果,此算法属于 Monte Carlo 算法。
算法的改进:重复进行 k 次实验,P(error′)≤2k1,时间复杂度为 O(kmax1(p,q,r)max2(p,q,r))。
1.4

- 很显然,得到的
cut 一定是一个割。因为去掉 cut 中的边后图 G 被分为了 C 和 V−C 两个顶点子集构成的图,两图之间再无边连接。
- 接下来只需证明
cut 是边数最少的割。
查到了这篇文章:https://www.cs.princeton.edu/courses/archive/fall13/cos521/lecnotes/lec2final.pdf
只是简短地提了一下这个算法与我们学到的 Karger’s algorithm 是等价的。
也在 CMU 找到了:https://www.cs.cmu.edu/~avrim/Randalgs97/lect0122
根据 MIT 的算法导论 http://www.cs.tau.ac.il/~zwick/grad-algo-13/mst.pdf ,最小生成树也可以使用收缩法进行构建,我们可以把最小生成树的构建过程看作是 2.6 节中的边的收缩过程,因为最小生成树的构建过程中使用 union-find data structure 将点合在同一个子图中时就等价与 2.6 中的收缩(采用 Prim 算法)。
不失一般性,不妨假设最终删除的边就是我们在构建最小生成树时加入的最后一条边(对 Prim 算法一定成立)。我们需要求的就是每次新加进来的边(除了最后一次,一共 n-2 条边)都不在最小割集顶点集 U 中的概率。
(否则,如果某一步中最小割集的边 u0 被加到了 T 中,最终输出结果 cut 必不包含 u0,不是最小割集)
整个计算过程和 2.6 是一样的:
事件 Ai 表示第 i 次新加进来的边不在最小割集顶点集 U 中。
P[∪i=1n−2Ai]=P[An−2∣∪i=1n−3Ai]⋅P[An−3∣∪i=1n−4Ai]⋮⋅P[A2∣A1]⋅P[A1]≤(1−2nkk)(1−2(n−1)kk)⋯=nn−2⋅n−1n−3⋅n−2n−4⋯31=n(n−1)2≥n22
P[∪i=1n−2Ai]≥n22=Ω(n21)
1.5


(1)
独立集的定义是:图的一组顶点集,其中任意两个互不邻接。
算法得到的 I 一定是独立集,对于任意两个邻接点 u0,v0,不失一般性,设 u0 的标签较小,如果 u0∈I,那么它的邻接点 v 一定在第 6 步中从 S 中删除了,不可能在后续被添加到 I 中。这样就证明了任意两个邻接点不可能同时在 I 中, I 是独立集。
拓展:
虽然可以得到独立集,但不一定是最大独立集,得到的结果是否是最大独立集与标签的选取有关,这里体现了随机性:
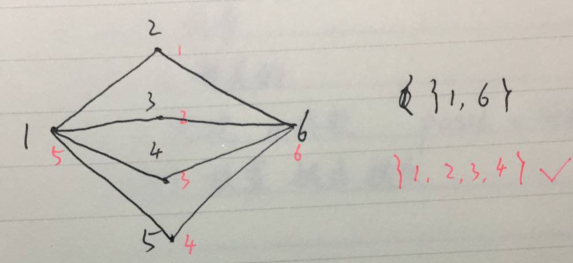
另外算法即使得到了最大独立集,也不能得到全部的最大独立集,例如:
最终结果为 {1,3},是满足输出条件的最大独立集,但并不是唯一的最大独立集,还有 {1,4},{2,4} 也是的
(2)
注意:下面的证明有问题,请忽略。此题有问题,无须再进一步讨论。
设 u 的所有邻接点分别为 v1,v2,⋯,vdu,将 <u,v1,v2,⋯,vdu> 按照标签大小从小到大排序之后的序列为 <vi1,vi2,⋯,vim,u,vim+1⋯,vidu>,因为『上述顶点集中u 的标签最小等价于 u∈I』:
P(u∈I)=P(im=0)+P(im=1)+⋯+P(im=du)P(im=0)=du+11
1.6

不失一般性,考虑升序排列的情况。
考虑 2 个元素的情况:
考虑 3 个元素的情况:
| 序列 |
置换次数 |
| 1, 2, 3 |
0 |
| 1, 3, 2 |
1 |
| 2, 1, 3 |
1 |
| 2, 3, 1 |
1 + 1 = 2 |
| 3, 1, 2 |
2 |
| 3, 2, 1 |
2 + 1 = 3 |
假设现在输入序列为 a1,a2,⋯,an,它是由 有序序列 经过 k 次倒置之后得到的结果。
想了半天没有想出来,查着查着查到了之前在行列式里面学过的逆序对数,发现这里的置换次数恰好等于逆序对数。
找到几个很有用的帖子:
- https://math.stackexchange.com/questions/2280185/inversion-count-and-number-of-transpositions
- https://math.stackexchange.com/questions/453686/what-is-the-expected-number-of-swaps-performed-by-bubblesort
核心的思想是:冒泡排序过程中,每一次置换都会让逆序对数恰好减 1,那么我们可以得到:
定理 1:逆序对数 = 冒泡排序置换次数
我们就是要求所有排列的逆序对数的数学期望:
定义:
Iij={1(ai,aj)是逆序对0(ai,aj)是正序对
E[Iij]=21
那么逆序对数的数学期望为:
E[i=1∑nj>i∑nIij]=i=1∑nj>i∑n21=2n(n−1)21=4n(n−1)
1.7

虽然函数值被篡改,我们可以用到关键条件:
F((x+y)modn)=F(x)+F(y)modm
定义新运算 ⊖,a⊖b=(a−b)modn
直接计算 F(z) 是不行的,对于未被篡改的数据正确率为 1,而对于被篡改的数据正确率为 0。
题目要求任意 z,我们应该做最坏的打算,假设 z 处的函数值恰好被篡改了:
均匀随机地选择 t∈[1,n−1],计算 F(z⊖t) 和 F(t),注意到 z⊖t 和 t 不是相互独立的,错误率为 P(error)=P[F(z⊖t)损坏∪F(t)损坏]≤(51+51)=52
算法运行 3 次,如果 3 次结果都不一样,返回第一次的结果。否则,返回出现次数最多的结果,
算法运行 1 次错误率为 p≤52
算法运行 3 次,算法最终出错等价于至少两次出错,概率为:
C32p2(1−p)+C33p3≤3×(52)2×53+(52)3=12544=0.352
这其中还要减去一个第一次算对了,后两次出错了的情况,此时会返回正确结果,因此错误率为:
(C32−1)p2(1−p)+C33p3≤2×(52)2×53+(52)3=12532=0.256
最终正确的概率大于 1 - 0.256 = 0.744
课堂练习
证明基于比较的随机排序算法不能突破下界 O(nlogn)。
利用姚期智不等式:
A∈DminA在Ip上的期望运行时间≤I∈ImaxR在I上的运行时间
通过 Google 找到 CMU 的资料。
(下文在输入数据量为 n 的前提下进行讨论。)
定理 1:任何基于比较的确定性排序算法,平均比较次数至少为 ⌊log2(n!)⌋。
根据定理 1,不管我们选择什么分布 p,最终的随机算法的时间下界都是 ⌊log2(n!)⌋=O(nlogn)。
定理 1 的证明:
