
由于百度人工智能比赛的需要,我们需要爬取新浪微博的微博数据,得到带表情的微博,将数据进行适当地处理,便于后续深度学习模型的训练使用。本文章用到的所有源代码请见 https://github.com/upupming/weiboAPI 。注意本文是一个探索过程,并不是一个总结。
基本思路
首先,我在 GitHub 上找到了 dataabc/weiboSpider 这个项目,并且立即 Star 和 Watch 了它,在我 Watch 之后看到开发者还在积极地给项目更新、回答 Issue,我感到很幸运。所以基本上打算在这个项目的基础上加以修改,符合我的需要。
注意:微博一共有三个比较不同的网站:
-
极简版的微博,没有现代化的 UI 界面,适合爬取。weiboSpider 就是基于这个 weibo.cn 进行抓取的。
-
现代化的微博网页,使用 Ajax 进行页面内数据的加载。我也向开发者提议使用网页使用的 Ajax API 进行抓取,作者回复说对项目的改动比较大,后续可能会在其他项目中实现。
-
手机版的微博网页,也是用 Ajax 来加载页面数据的。
接下来我们只考虑 weibo.cn,有了 weiboSpider,要爬取数据就简单很多了,我需要做的也不算特别多。但是有几点比较难以处理的事情先需要明确一下解决方案。
微博的表情有的是用图片表示的(比如 ![]() ),有的则是用 Unicode 表示的(比如 😀),有的则是直接用『[…]』表示的(比如 [黑桃]️)。
),有的则是用 Unicode 表示的(比如 😀),有的则是直接用『[…]』表示的(比如 [黑桃]️)。
- 对于图片表情,weiboSpider 是直接把它们忽略掉,最终的爬取结果里面没有这些表情,我可以对它进行修改,用图片的
alt属性表示表情,然后建立一个【表情名称 -> 表情图片/网址】的字典。 - 对于 Unicode 表情,无需做任何处理。
- 对于文字表情,我们需要人工去判断这些表情与 Unicode 中的哪些表情对应。
表情数据库搭建
Unicode 表情
所有的 Unicode 参见 https://unicode.org/emoji/charts-12.0/full-emoji-list.html,简单起见,我们直接使用 GitHub 支持的所有 emoji,参见这里,使用 regexr.com 处理后得到下面的文本:
unicode.txt
Copied from: https://gist.github.com/roachhd/1f029bd4b50b8a524f3c#gistcomment-2585127 |
在发布微博之后,看到如下内容:

使用 weiboSpider 爬取得到的结果如下:
爬取结果
微博内容: |
从实验结果看到,使用 Unicode 发布的表情,有一些保留原样还是『Unicode 表情』,有些则被转换成了『文字表情』,还有一些转换成了『[emoji]』这样的文字表情,也就是说 weibo.cn 根本无法处理这些表情。
因此我们分情况进行处理:
-
保留原样的 『Unicode 表情』
不做任何处理
-
转换为了『文字表情』的 Unicode 表情
建立『Unicode 表情』->『文字描述』(unicode2Desc)和『文字描述』->『Unicode 表情』(desc2Unicode)两个哈希表(python 中的字典)。
-
转换为了『[emoji]』的 Unicode 表情
总共只有 19 Unicode 个表情是这种情况,因为这些表情不太常见,所以可以直接忽略。
经过反复思考,我觉得这样处理还是太过麻烦,因此决定:放弃使用 weiboSpider,自己写一个基于 Ajax API 的爬虫,爬取 weibo.com 的内容。因为 weibo.com 对 Unicode 表情处理的是很好的,不会用文字去展示。
etree 对 HTML 进行处理主要是要学会 xpath 搜索功能,在 Chrome 中有一个 Copy XPath 功能很有用,再结合 lxml 的文档和这个看一下就能够理解了:
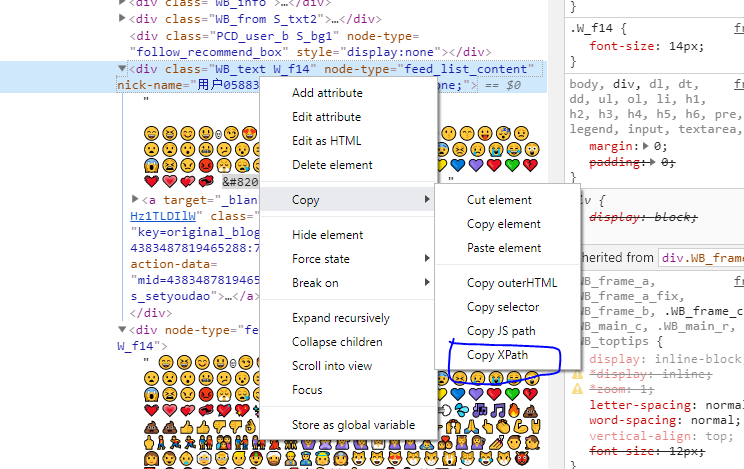
因此我构造出的 XPath 为 //div[@node-type='feed_list_content_full']。
但是有一个小问题,在默认情况下,长微博是不展开的,并在末尾有一个『展开全文』:
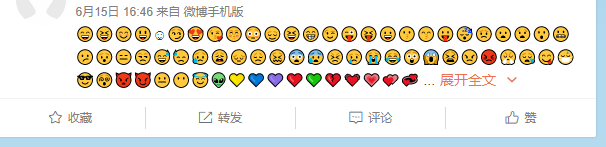
通过调试我发现未展开的时候,HTML 中并没有微博的全部内容,此时我打开 Network 页,选中 XHR,点击页面中的『展开全文』,可以看到多了一个网络请求:
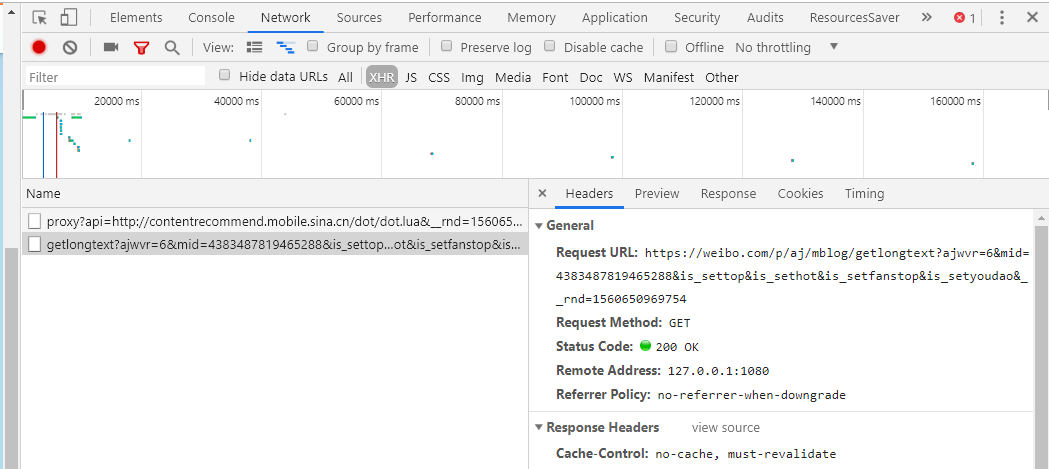
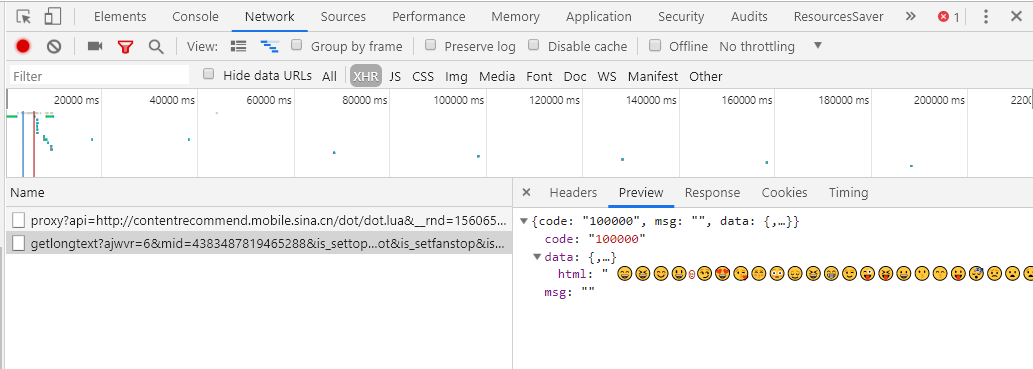
我们可以通过 Postman 来复现这个请求:
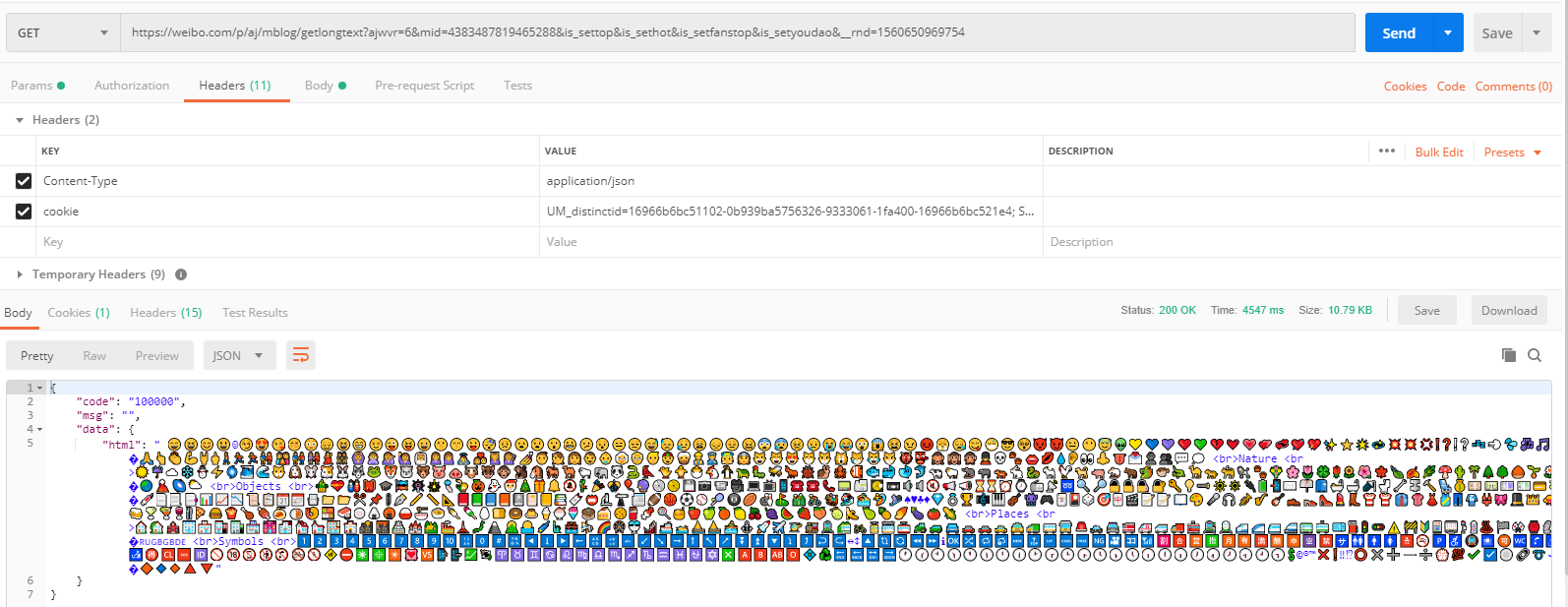
分析以下几个参数的意义:
ajwvr:6 不清楚含义,但是我见过的所有爬虫都设置为了 `6` |
所以这里最关键的就是 mid 这个参数了,我们怎么拿到这个参数呢?有一个最简单的想法是直接利用 etree 对得到的 HTML 进行搜索,对于有『展开全文』的微博,其外部都有一个类似 action-data="mid=4374832440848723" 的属性。weiboSpider 的做法是根据微博中有没有 <a> 标签内的文本为『全文』来判断一条微博是否是长微博,是长微博的话,再次对服务器发起请求,获取这条长微博的所有内容。
借鉴 Ajax 爬去的思想,我还是想看看有没有更加简单的 API。
经过不断测试发现 weibo.com 比较麻烦,有多个 page,page 之内分为 2 个 pagebar,也就是说一页的内容是分两次加载的。但是 m.weibo.cn 就没有这个分页问题,所有微博都是随着屏幕下滑逐渐加载的。所以 API 也更加简单。
m.weibo.cn 的 API
获取用户基本信息
https://m.weibo.cn/api/container/getIndex?type=uid&value={}
type: uid |
返回结果:
获取用户微博
https://m.weibo.cn/api/container/getIndex?type=uid&value={}&containerid={}
type: uid |
可以看到这里只是多了一个 containerid,而就是获取用户信息时拿到的 data->tabsInfo->tabs 数组的第二个值,其 title 为 微博。也就是说我们可以在获取用户信息之后,拿到其微博的 containerid,从而继续调用 API。
可以借鉴一下这篇文章,containerid 其实是以 uid 结尾的,
m.weibo.cn/status/+id是微博详情页。
返回结果:
但是要如何连续爬取第二页呢?根据这篇文章,可以传入一个 page 参数,我们的请求 url 就变成了 https://m.weibo.cn/api/container/getIndex?type=uid&value={}&containerid={}&page={}。
并且我们可以根据返回结果中的 最后发现返回的结果中并没有总页数,我感觉手机版的微博本身就是不需要总页数的(因为一直往下在滑刷新页面),所以这个 API 不返回总页数。最终我是直接根据返回结果,如果出现下面的结果就终止循环:cardlistInfo->total 拿到总页数,一共是 1012 页。利用循环获取到所有页面的微博即可。
{ |
这是一个想法,但是我又想到了另外一个做法,就是:页数=微博条数/每页微博条数+1,更加简单。
获取微博详细内容
对于较长的微博,上面的获取方式并不会直接返回全部内容,而是带有『全文』的链接:
😄😆😊😃☺️😏😍😘😚😳😌😆😁😉😜😝😀😗😙😛😴😟😦😧😮😬😕😯😑😒😅😓😥😩😔😞😖😨😰😣😢😭😂😲😱😫😠😡😤😪😋😷😎😵👿😈😐😶😇👽💛💙💜❤️💚💔💓💗💕💞 ...<a href="/status/4383487819465288">全文</a> |
这个时候我们就不得不去获取这条微博的详细内容了,通过前往 https://m.weibo.cn/status/4383487819465288 抓包发现可以使用下面的 API:
https://m.weibo.cn/statuses/extend?id={mid}
mid: 4383487819465288 |
返回结果:
具体的做法是对每一条微博通过 XPath 判断是否有『全文』链接,如果有的话,再次请求这条微博的获取详细内容。
图片表情
图片表情的处理方式是,建议一个『文字描述』到『图片URL』的 dict,同时还把这些图片 URL 抓取到本地一下,以备查看。
由于图片表情在返回的博文中是以 HTML 格式表示的,我们需要用 etree 进行处理:
html = etree.HTML(text) |
评论、粉丝和关注、转发爬取
有了微博信息还不够,我们需要对评论进行爬取。因为评论短小、更适合应用表情。为了爬取能够循环下去,我们还需要对粉丝和关注所有进行爬取。
转发微博的话也占了很大一部分,转发内容具有重复性,不是我们需要的,所以我是把原始内容发布者作为一个新的爬取对象进行爬取。我们可以维护一个 crawling_user_ids 数组存储当前所有正在被爬取的用户防止重复爬取。
转发 API
还是使用前面提到的『获取用户微博』的 API,如果是转发的微博的话,会有一个 retweeted_status 对象包含了几乎被转发微博的所有的信息,里面的 retweeted_status->user->id 就是被转发者的 uid。我们根据这个微博重新创建一个 WBSpider 对象,抓取被转发的用户。
另外,有这样一个 API:
https://m.weibo.cn/statuses/show?id={}
id: HyZVegYAP |
得到的结果如下:
但是我们并不需要用到这个 API,因为我们不关注转发内容,只关注被转发者的 uid。
评论获取 API
https://m.weibo.cn/api/comments/show?id={}&page={}
id: 4383183661430868 |
得到的结果如下:
其中的 total_number 就是总的评论数量,max 是总页数。我们可以根据 max 来进行循环,获取到所有的评论信息。
另外,我发现这个 API 会出问题,请求几页之后就不行了(后来发现是需要登录),我抓取到的评论 API 是这样的:
https://m.weibo.cn/comments/hotflow?id=4383183661430868&mid=4383183661430868&max_id_type=0
按照返回的:
max_id: 314345666829623 |
作为第二次请求的参数进行循环请求即可,经过测试发现最后终止条件是这两者都为 0。
另外,我们还需要利用多线程增加并行处理来加快爬取速度。通过维护『被抓取用户池』来并行抓取,详情可以参考我的代码。
评论爬取这块还有一个坑,应该是微博自己做了反爬限制,所以直接用 python 的 request 会出现 302 FOUND 并把你重定向到微博的登录网址。我后来使用 chromedriver 才发现微博的限制是这样来进行重定向的:
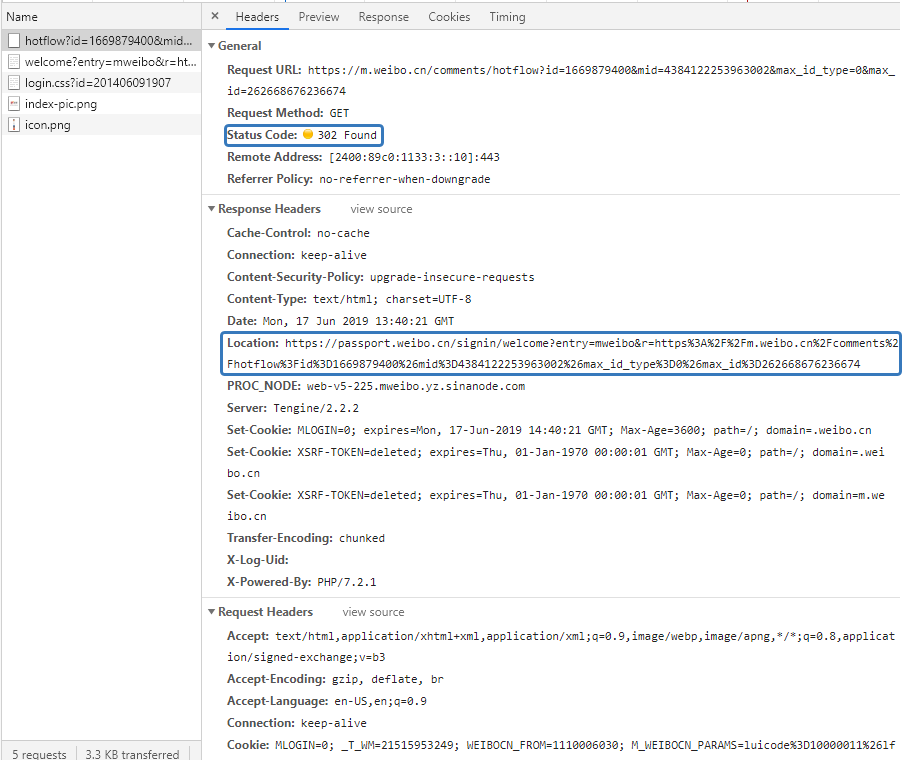
但是在 Chrome 直接输入就会返回正常的数据。我又尝试了 Chrome 的无痕浏览,发现也会被 302 重定向,因此我推测是没有登录的原因,因此我们可以写一个登录的步骤:
def login(self): |
所以最终的总结还是:虽然爬取 m.weibo.cn 的微博正文不需要 Cookie,但是第一页之后的评论还是需要 Cookie 的,我以为是 request 自身的原因还将 request 换成了 chromedriver。
最后,我们把评论人的 uid 也要加入『被抓取用户池』中进行抓取,注意并行度不能太高,否则会出现『请求过于频繁』,我们可以维护一个等待队列:
def start(self): |